In this section we review some important concepts about objective functions . We assume throughout that is (at least) continuously differentiable.
Convex functions¶
Recall from Chapter 2 two useful characterizations of convex functions.
Smooth functions¶
Another important notion is that of smoothness of a function , which relates to Lipschitz continuity properties of its gradient .
In particular, functions that are not differentiable, or differentiable with non-continuous derivatives are nonsmooth functions. Below are two important properties of smooth functions. On the other hand, if is -smooth, then this implies continuous differentiability of .
Proof
The proof is adapted from Wright & Recht (2022). Let be continuously differentiable. Recall the integral version of Taylor’s theorem
for any . Then given we can build the quantity (using )
Using -smoothness of , we bound the integrand as
Finally, by integrating the upper bound
and thus the desired result
Noting we observe that ; ; . This means that is upper bounded by a quadratic that takes, at , the same value and gradient , with Hessian (curvature is in all directions).
Remark The notation means that the matrix is positive semidefinite, or in other terms, the eigenvalues of the Hessian are upper-bounded by .
Proof
The proof is adapted from Wright & Recht (2022). We suppose that is twice continuously differentiable.
Suppose that is -smooth. Let and using Property 1, one gets
On the other hand, using Taylor’s theorem (second-order mean-value form) one gets
Comparing the two expressions we get the inequality
In the limit , we get (using continuity of the Hessian). Taking as any of eigenvectors of shows that the associated eigenvalues is bounded by . Hence, .
Suppose that for all . As a result, the operator norm where the are the eigenvalues of . Since by assumptions all eigenvalues are smaller than (in absolute value), we get . Now, recall another version of Taylor’s theorem, i.e.,
We can apply directly this result to bound as
which shows that is -smooth.
Strong convexity¶
Remarks
the definition can be extended to non-differentiable functions
if is -strongly convex, then is also strictly convex
the function is -strongly convex iff is convex
The following properties are direct consequences of strong convexity and / or smoothness applied to convex functions.
This result shows that Hessian eigenvalues are lower-bounded by .
Proof
. Suppose that is -strongly convex. For any and , Taylor’s theorem gives
Using the strong convexity property, one gets
Plugging the two statements into one another, one gets the inequality
As before, taking the limit , one has and thus .
. Suppose that . Using once again Taylor’s theorem,
Since this means that , hence for any one has , i.e., . Thus,
and
which shows that is -strongly convex.
Another property is the following.
Proof
Let be a twice differentiable convex function.
suppose that is -smooth. Then by Property 2, . Moreover, since is convex, , so that .
Suppose that . Then, in particular . By Property 2, is -smooth.
Summary: smoothness and strong convexity¶
The following numerical example illustrates how for a given function , its properties (convexity, smoothness, strong convexity) permit to “bound” the function on its domain by simple (linear or quadratic) functions.
Let us consider . The function is obviously convex, -smooth (for any ) and -strongly convex (for any ). Then we can display the upper and lower bounds induced by considering the smoothness, convexity and strong convexity alone - or by combining them. These bounds become ultimately important when one wants to characterize convergence properties of optimization algorithms.
Source
import numpy as np
import matplotlib.pyplot as plt
import palettable as pal
from ipywidgets import interact, FloatSlider
cmap = pal.colorbrewer.qualitative.Paired_4.mpl_colors
myblue = cmap[1]
mygreen = cmap[3]
def f(x):
return 0.5*x**2
def gradf(x):
return x
def upper_bound(x0, x, L):
y = f(x0) + gradf(x0)*(x-x0) + 0.5*L*(x-x0)**2
return y
def lower_bound(x0, x, m):
y = f(x0) + gradf(x0)*(x-x0) + 0.5*m*(x-x0)**2
return y
x = np.linspace(-1,2, 100)
L = 1.5
m = 0.6
def plot_bounds(x0):
fig, ax = plt.subplots(figsize=(12, 8), ncols=2, nrows=2, sharex=True, sharey=True)
# L-smoothness
ax[0, 0].plot(x, f(x), color=myblue, linewidth=2)
ax[0, 0].plot(x, upper_bound(x0, x, L), color=mygreen, linewidth=2)
ax[0, 0].plot(x, upper_bound(x0, x, -L), color=mygreen, linewidth=2)
ax[0, 0].fill_between(x, upper_bound(x0, x, -L),\
upper_bound(x0, x, L), alpha=0.1, color=mygreen)
ax[0, 0].scatter(x0, f(x0), marker='o', color='k', zorder=10)
# strong convexity
ax[0, 1].plot(x, f(x), color=myblue, linewidth=2)
ax[0, 1].plot(x, lower_bound(x0, x, m), color=mygreen, linewidth=2)
ax[0, 1].fill_between(x, lower_bound(x0, x, m), 2, alpha=0.1, color=mygreen)
ax[0, 1].scatter(x0, f(x0), marker='o', color='k', zorder=10)
# L-smooth, convex
ax[1, 0].plot(x, f(x), color=myblue, linewidth=2)
ax[1, 0].plot(x, upper_bound(x0, x, L), color=mygreen, linewidth=2)
ax[1, 0].plot(x, upper_bound(x0, x, 0), color=mygreen, linewidth=2)
ax[1, 0].fill_between(x, upper_bound(x0, x, 0),\
upper_bound(x0, x, L), alpha=0.1, color=mygreen)
ax[1, 0].scatter(x0, f(x0), marker='o', color='k', zorder=10)
# L-smooth, m-strg convex
ax[1, 1].plot(x, f(x), color=myblue, linewidth=2)
ax[1, 1].plot(x, upper_bound(x0, x, L), color=mygreen, linewidth=2)
ax[1, 1].plot(x, lower_bound(x0, x, m), color=mygreen, linewidth=2)
ax[1, 1].fill_between(x, lower_bound(x0, x, m),\
upper_bound(x0, x, L), alpha=0.1, color=mygreen)
ax[1, 1].scatter(x0, f(x0), marker='o', color='k', zorder=10)
# clean
for axis in np.ravel(ax):
axis.xaxis.set_visible(False)
axis.yaxis.set_visible(False)
for side in ['top','right','bottom','left']:
axis.spines[side].set_visible(False)
fig.tight_layout()
ax[0, 0].set_ylim(-.2, 1)
labelsize=20
ax[0, 0].set_title('$L$-smooth', size=labelsize, y=0.9)
ax[0, 1].set_title('$m$-strongly convex', size=labelsize, y=0.9)
ax[1, 0].set_title('$L$-smooth, convex', size=labelsize, y=0.9)
ax[1, 1].set_title('$L$-smooth, $m$-strongly convex', size=labelsize, y=0.9)
plt.show()
interact(plot_bounds, x0=FloatSlider(value=0.5, min=-1, max=2, step=0.01, description='$x_0$'));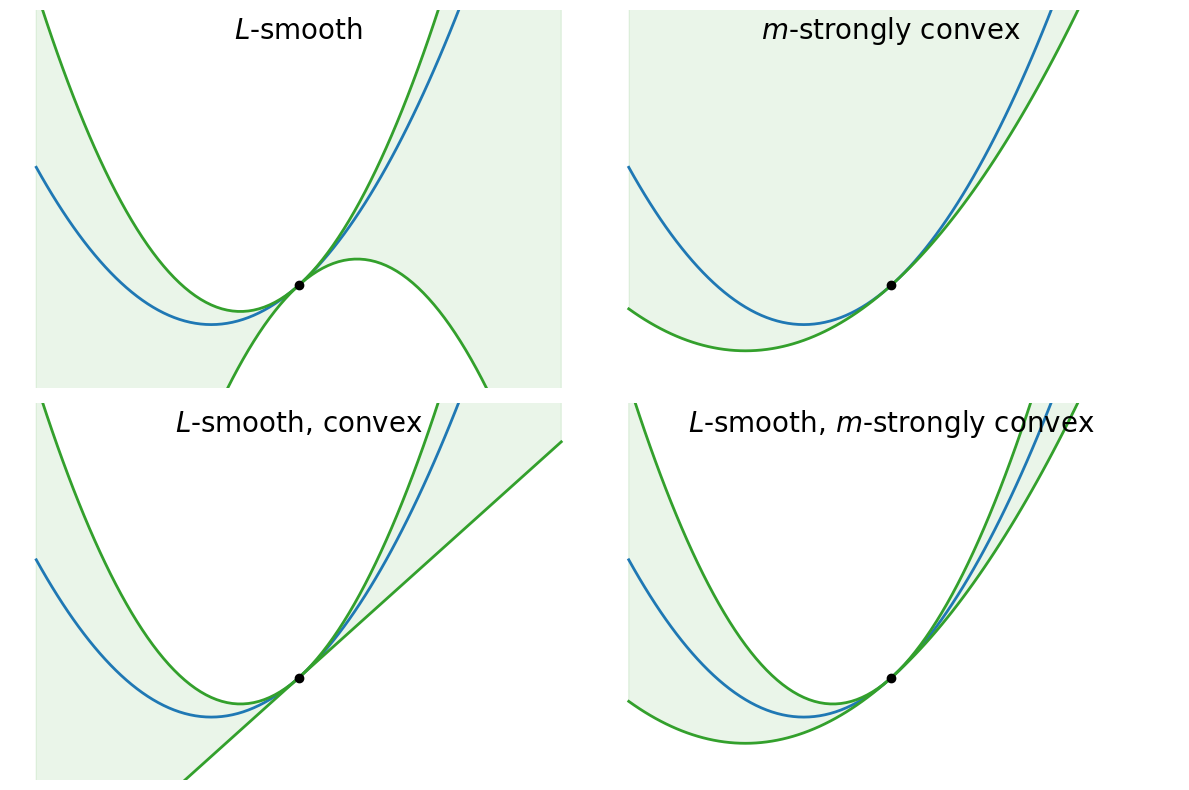
Assessing convergence¶
The kind of convergence guarantees strongly depend on the regularity properties (convexity, smoothness, strong convexity) of the objective :
Convergence in objective function values: In this case, we bound the distance to the optimal value . This condition is usually weaker and requires less assumptions about .
Convergence in iterates: Here, we bound the distance between the current iterate and a optimal point , . This usually requires strong convexity of .
In some cases, both type of convergence can be related.
- Wright, S. J., & Recht, B. (2022). Optimization for data analysis. Cambridge University Press.